Annotationツール比較:labelImgとVoTT(YOLO・SSD両対応のデータセット)
最近、物体検出の独自モデル構築にどっぷりはまっています。
2018/03にYOLOv3が出てからというもの「SSDより良いらしいよ!」という噂を良く聞くようになりました。そこで、今まで作ったSSDの教師データを流用する方法を探し、YOLOによるオリジナルモデルの検証をしたいと考えました。
学習に使う教師データはAnnotationツールで作成するのが一般的です。
Annotationツールとは:対象となるデータに対して正解ラベル(タグ)や対象物の座標等関連する情報を注釈として付与するツールです。
今までSSDの学習データをlabelImgで作っていましたので、まずlabelImgの最新版を検証し、次にMicrosoftのAnnotationツールVoTTも使ってみました。(作業環境はWindows 10 Professional 64Bitです)
ソフトウェア開発プラットフォーム"GitHub"をチェックしてみましょう。
現時点のlabelImgとVoTTのスター数などの比較です:
- tzutalin/labelImg
- microsoft/VoTT
https://github.com/tzutalin/labelImg/
Star:7031 Fork:2449
windowsで簡単インストールしたい方はこちらから:
https://github.com/tzutalin/labelImg/releases/tag/v1.8.1
https://github.com/Microsoft/VoTT/
Star:1354 Fork:278
labelImgが勝っていますね。
早速試してみたい方はURLからダウンロードしてみてください。
labelImg
UIのアイコンが分かりやすく、マニュアルがなくてもすぐ操作できます。
画面はこんな感じです。
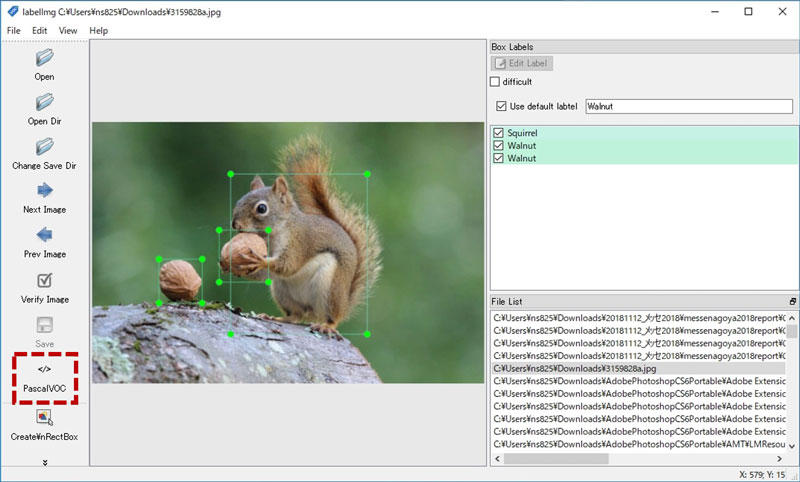
昔のバージョンではYOLO形式に対応していなかったのですが、現在一番新しいバージョンのlabelImg v1.8.1はYOLO形式にも対応しています。
左側の「PascalVOC」ボタン⇔「YOLO」ボタンが交互に切り替わります。表示されているフォーマットで保存されます。
矩形を付与する際に、補助線が出ることや、一度出力したxmlやtxtファイルを自動で再読み込みしてくれるので、便利ですね。
ただし、ディレクトリのルートに日本語が入っていると、ファイルが正常に読み込めなくなるので、英語を使いましょう。
「View」→「Auto Save Mode」を選択すれば、「Next Image」ボタンを押すだけで自動保存できます。
ショートカットキーと組み合わせて使えば、2-3秒間で1枚の画像を処理できます。
とは言え...以前作ったSSD用のPascalVOC形式のxmlファイルをYOLO形式のtxtに変えるために、一枚一枚「PascalVOC」ボタンをクリックしてYOLO形式で再保存しないといけないです。 単純なボタンクリック作業とは言え、画像枚数が多くなると気が狂いそうになりますね。
既存データを効率的に変換するため、少し探してみました。後述するxml2yolo.pyというコンバートプログラムがありました。気が狂わなくて良かったです。
VoTT v2
続いて、最近どんどん進化しているVoTTを見てみましょう。
現在最新バージョンはVoTT v2.1.0です。開くと、まず「Projest Settings」というパネルが出てきます。
一瞬「なに?」と迷うと思いますが、記入内容について簡単に説明します。
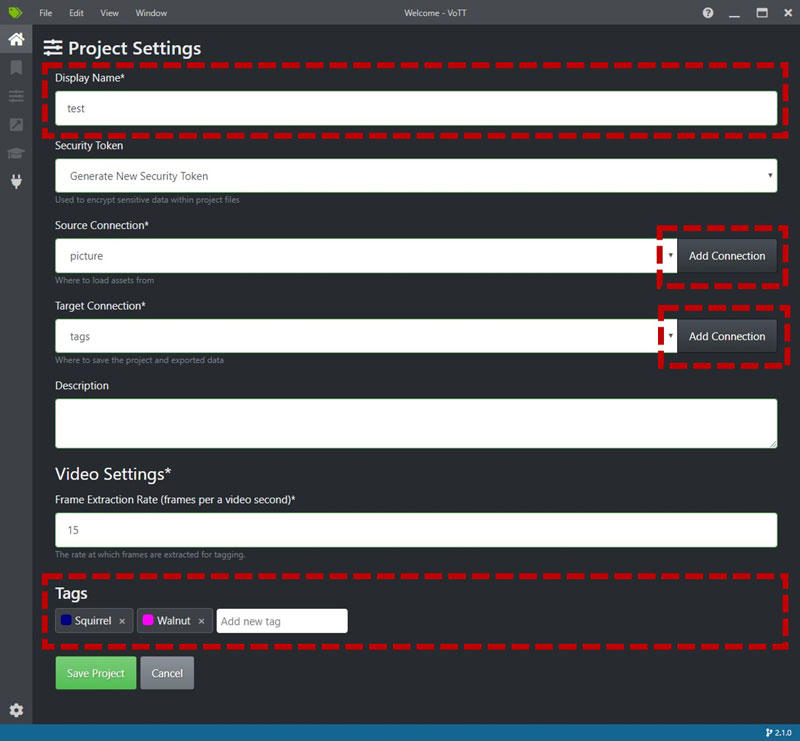
- Display Name:プロジェクト名
- Security Token:セキュリティの設定ですが、必須ではないので無視しても大丈夫
- Source Connection:画像を読み込む時のフォルダ
- Target Connection:ラベルを書き出す時のフォルダ
- Video Settings:ビデオにラベルを付ける時のフレーム数
- Tags:ラベル
始まる前に、まずは少なくともプロジェクト名、Source Connection、Target Connectionとラベルをちゃんと設定しないといけないようです。
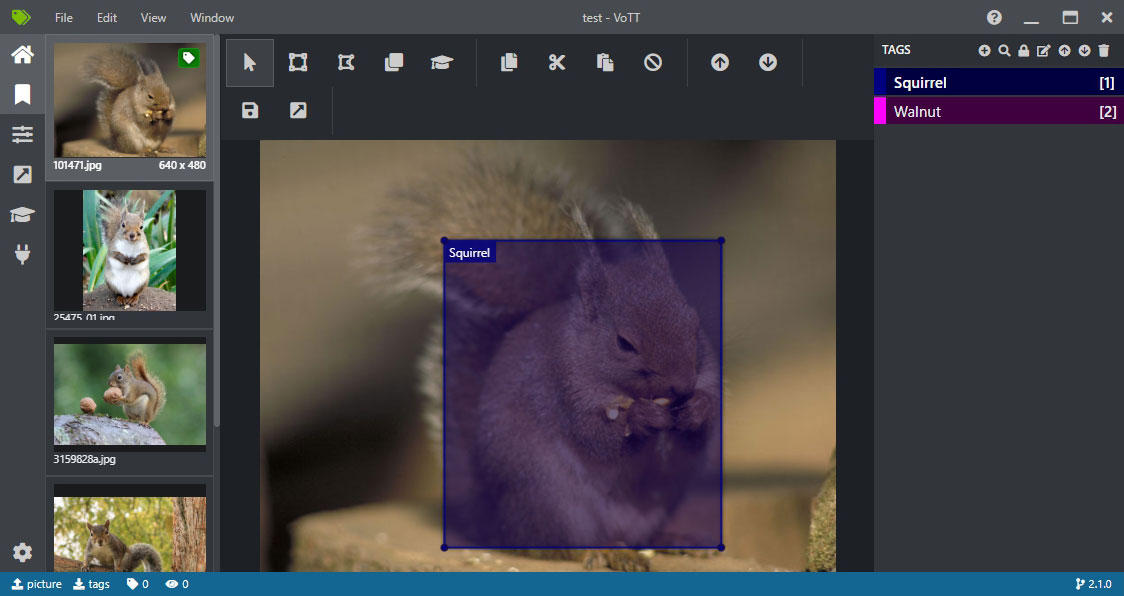
VoTTの一番の強みは、ビデオのフレームを切り出さなくても、直接にラベルを付けられることです!
使い方はlabelImgに似ていますが、左側に画像のサムネイルがちゃんと表示されています。ファイル名しか表示されないlabelImgより分かりやすいです。
ビデオにラベルを付ける時も同じやり方ですので、操作しやすいですね。
「Active Learning」に更に目玉機能が潜んでいます!
- Predict Tag:「Model Provider」のモデルを使って、画面上に写っているものを自動認識
- Auto Detect:前のフレームのラベル情報を次のフレームに引き継ぐ(特にビデオにラベル付けの時に役立ちます。)
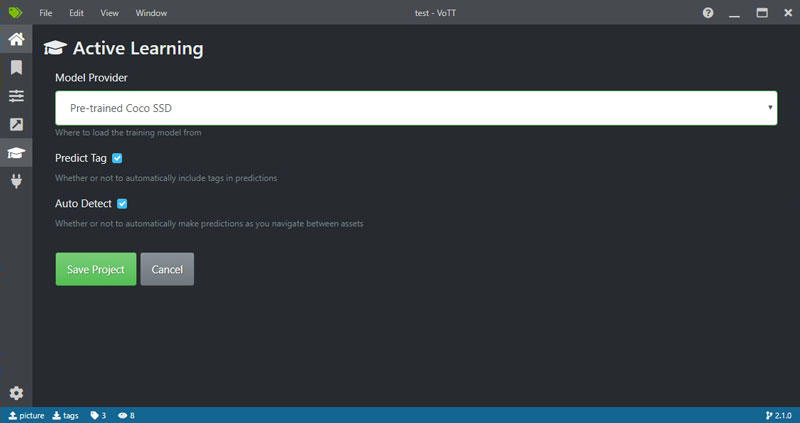
(残念ながら、自動認識の結果、リスがクマとして認識されましたが...デフォルトのモデルではなく、自作のモデルを使えばもっと精度を高められるのでしょうか?)
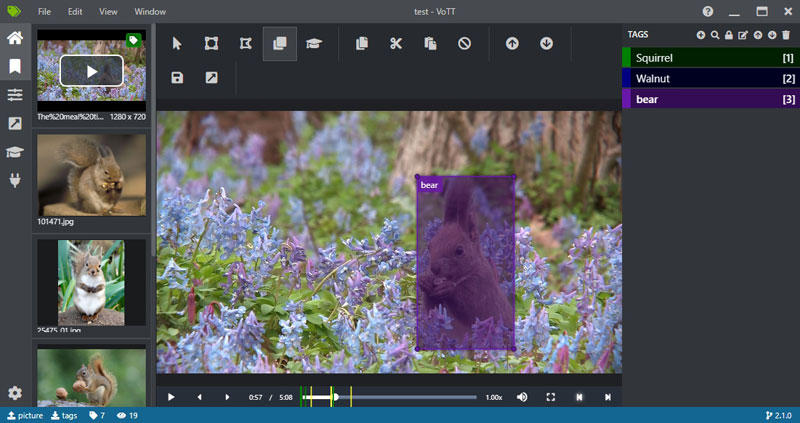
一見使いやすいVoTT v2ですが、致命的な弱みもあります...
まずは、書き出したファイルのファイル名は画像や映像と一致していなく、ランダムです...学習する時のリネーム作業が必須のようです。
もう一つですが、どうやらv2のバージョンはYOLO形式を対応していないようです。(使えないじゃん!)
VoTT v1
v1のバージョンに戻ってみると、ちゃんとYOLO形式に対応していたようですが、なぜv2で消えたんでしょう。ちょっと混乱が見えますね。
UIは現在よりシンプルですが、画像と映像両方とも使える所は変わりがありません。
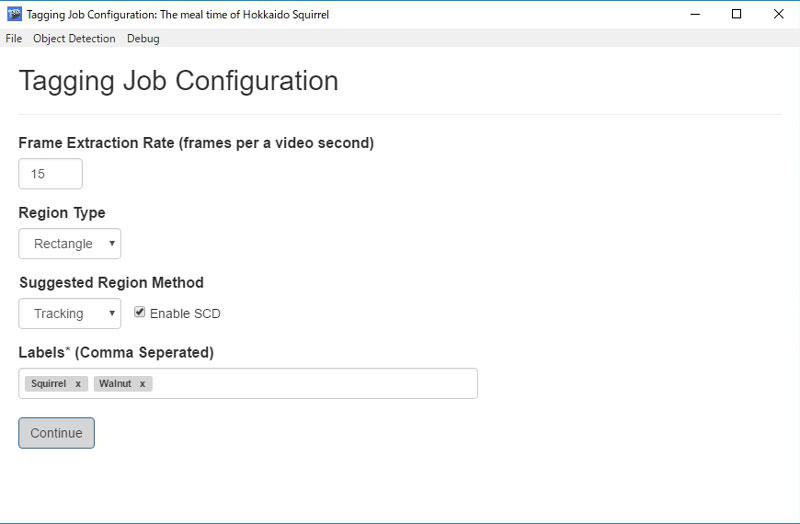
映像を選んだら、下記のような画面が出てきます。フレーム数とラベルを記入して開始です。
ここの「Tracking」という機能はv2の「Auto Detect」機能と同じく、前のフレームのラベルを引き継ぐことができます...
が、v1の最新バージョンが私の環境ではうまく動かなくて、v1.0.6辺りならちゃんと作動できるようになりました。
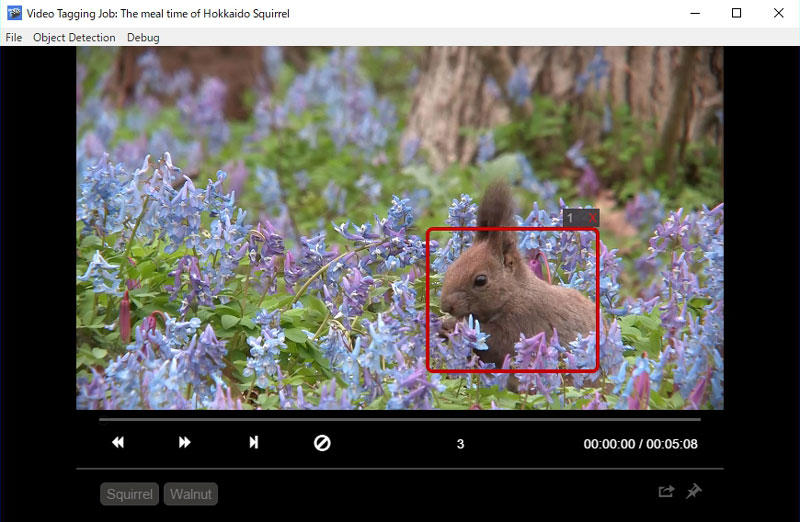
書き出す時に対応しているのは「Fast-RCNN」と「YOLO」だけですが、書き出したファイル名はソースファイルと一致しているので、 (今のところ)v1のほうが使いやすいですね。
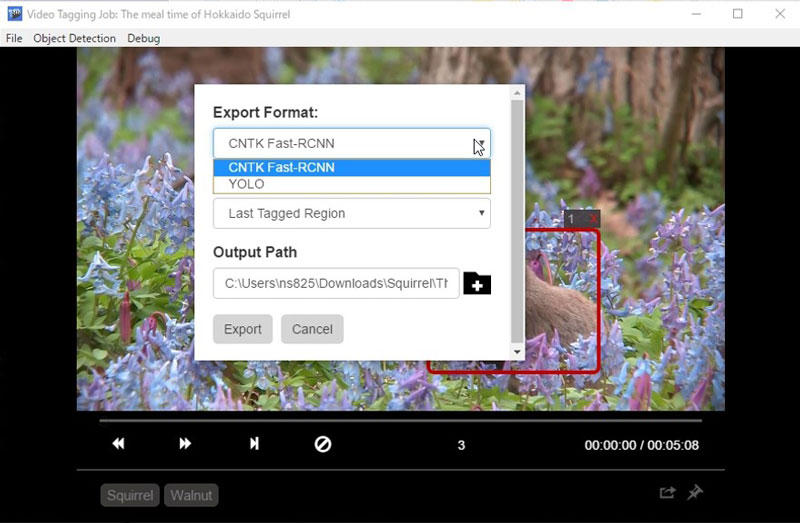
まとめ:YOLO形式ファイル作成は何を使えば?
使い勝手と書き出す時のファイル名問題も考えれば、画像ならlabelImg、映像ならVoTT v1がおすすめです。
ただし、VoTT v1は今後アップグレードされないので、v2の改善に期待するしかないです。
もしSSDとYOLO両方とも同じデータセットを使う可能性がある場合、一番便利なのは、やはりまずPascalVOC形式のxmlを作って、後ほどYOLO形式に一括変換することでしょう。
変換の仕方はここを参考:
アノテーションファイル変換(VOC XMLからYOLO テキストへ)
https://qiita.com/mdo4nt6n/items/bd909df26d159401d166
学習データはディープラーニングの基礎とは言え、気長な単純作業でもあります。
今後、この単純作業を楽にするような画期的なアノテーションツールが出て来るんでしょうね~。楽しみですね。
▼この記事を書いたひと

R&Dセンター 陸 依柳
撮影、お城、戦国、ICT、サブカルチャー...常に面白く、新しいものに惹かれるタイプです。地方の戦国イベントによく参加しています☆