オープンイノベーション【オープンイノベーション】vol.26:何がどう変わった?Ultralytics YOLOv8のレビュー

Ultralytics YOLOv5の公開元であるUltralytics社から、2023年1月にYOLOv8が公開されました。
Ultralytics ウェブサイト:https://www.ultralytics.com/ja
公式によると、YOLOv8は以前のYOLOバージョンの成功に基づいて構築され、パフォーマンスと柔軟性をさらに高めるための新機能と改善が導入された最先端の最先端モデルとのことです。
※YOLO=You Only Look Once(見るのは一度だけ)の略称
引用:https://github.com/ultralytics/ultralytics
ここでは、WindowsにYOLOv8の環境を構築して動かしてみた内容をまとめました。
YOLOv8はYOLOv4と比べて手法や機能が変化しているため、何が新しくなったのかを見てみましょう。
また、公式のドキュメントには環境構築方法や各モードについての詳細が記載されていますので、こちらもご参照ください。
Ultralytics YOLOv8 Docs:https://docs.ultralytics.com/
YOLOv8をWindowsで動かす
YOLOv8はpip、conda、Dockerを含む様々なインストール方法を提供しています。
今回は、Pythonのvenv仮想環境のもと、pipによる環境構築を行いました。
・必要な環境
Windows or Linux or Docker
Python >= 3.8
Pytorch >= 1.8
・今回構築した環境
Windows10 Pro
GPU: NVIDIA GeForce RTX 2080 SUPER
CUDA: 11.7.1
cudnn: 8.8.0
Pytorch: 1.13.0+cu117
Python: 3.8.8
YOLOv8のインストール
当社では、YOLOv3、v4をWindows環境で使う際、Cで書かれたバイナリを永らく使っていました。そのためには、CのMake環境、Makeファイルの修正などを経てVisualStudioでのWindowsバイナリへのビルドが必要でした。またPCやGPUの環境に左右されることが多く、インストールでエラーが発生することも少なくありませんでした。
YOLOv8では、Pytorch、Pythonの環境が整っていれば、あとはultralyticsパッケージをインストールするだけで準備完了となります。YOLOv4と比較してエラーも少なくなり、作業環境構築の手間と時間がかなり削減されました。
ultralytics パッケージ:https://pypi.org/project/ultralytics/
【コマンド】
python -m pip install torch==1.13.0+cu117 torchvision==0.14.0+cu117 torchaudio==0.13.0 --extra-index-url https://download.pytorch.org/whl/cu117
python -m pip install -U ultralytics
学習(独自モデル作成)をやってみる
YOLOv8にはモデルサイズが異なるn, s, m, l, xの5パターンのモデルが用意されています。
今回は、YOLOv8nに対し独自データでモデル作成を行いました。
学習データの準備
YOLOv8では、YOLOv4と同様に画像と併せてアノテーション情報(YOLO形式テキストファイル)が必要となります。
また、画像データと併せてyamlファイルを準備します。
yamlファイルとはデータセット設定ファイルのことです。クラス、訓練セット、検証セットのパスなどを含むデータセットの構造を指定するためのもので、YOLOv4ではdataファイルとして用意していました。
なお、dataファイルとyamlファイルでは記述の仕方が異なるため、必要に応じて編集してください。
学習時パラメータ
画像数:(train)110枚+(test)55枚
クラス数:4
batch_size=16 ※32だと途中停止
image sizes=640
epoch=200 ※デフォルトは300
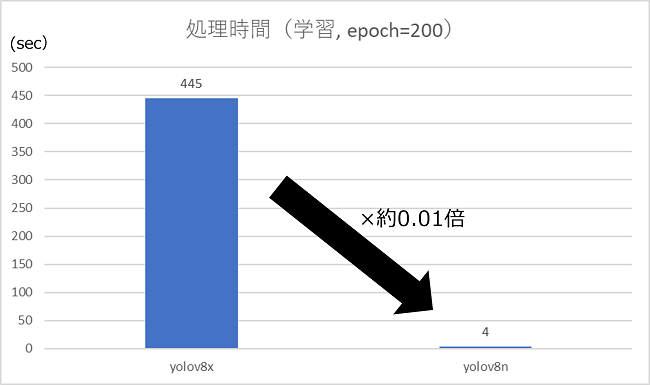
学習の処理時間
同じ学習データ、パラメータを用いても、モデルのパターンによって学習時間は大きく変動します。
下記はYOLOv8nとYOLOv8xとで同じ学習データ、パラメータのもと学習したときの処理時間です。
| 学習時間(epoch=200) | 1epochの処理時間 | |
|---|---|---|
| YOLOv8x | 7時間25分 | 2.23分 |
| YOLOv8n | 4分 | 0.02分 |
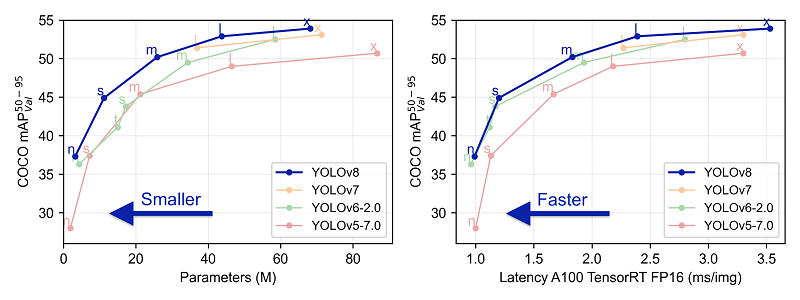
モデル性能
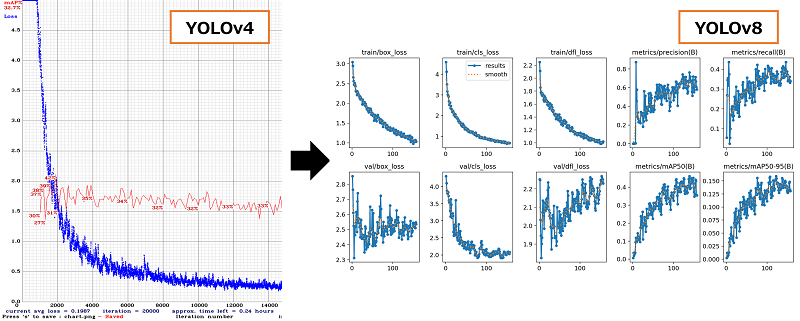
YOLOv4とYOLOv8との学習時グラフの変化
YOLOv4では、学習と同時にmAPとLOSSに関するグラフが自動で作成されていました。
これに対し、形式は異なりますが、YOLOv8でも同様のグラフが数種類作成されるため、その結果から独自モデルを評価できます。
また、最も精度がよい重みファイル(best.pt)に対し、自動的に性能評価の結果も出力してくれます。
YOLOv8の性能評価方法
YOLOv8にはvalモードというものが存在しており、model.val()で実行します。
このvalモードを使うことで、モデル作成時と同様にモデルの性能評価を行うことができます。
valモードを使う場合は、アノテーション情報を持つ画像データが必要です。
今回は学習データの中からテスト用に分類したものを使いました。
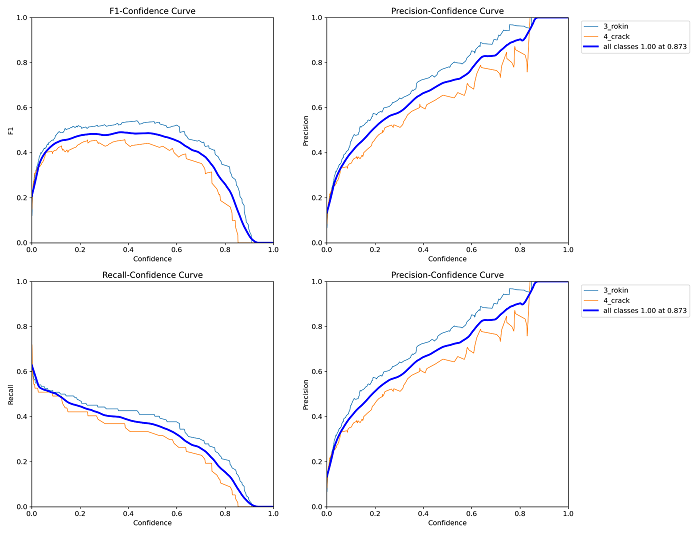
各クラスの性能評価の結果
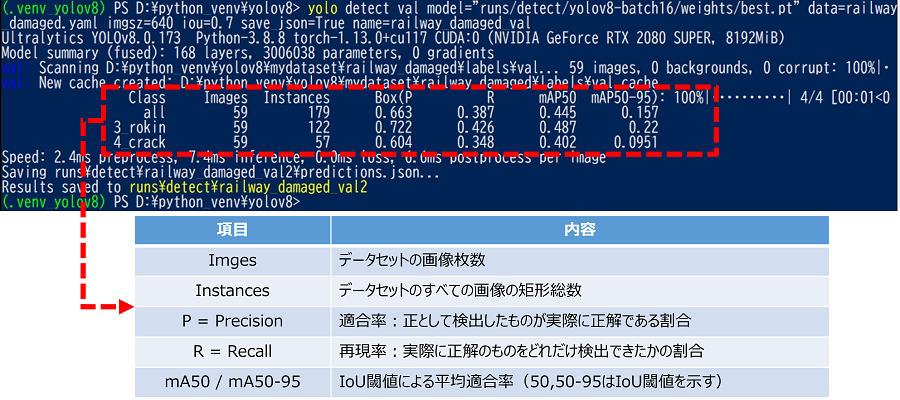
精度検証の各グラフ
検出速度
YOLOv4とYOLOv8とで、まったく同じ動画をMS COCOモデルで検出したときの処理速度を比較してみました。
4Kと2Kの動画、そして静止画に対しての結果になります。
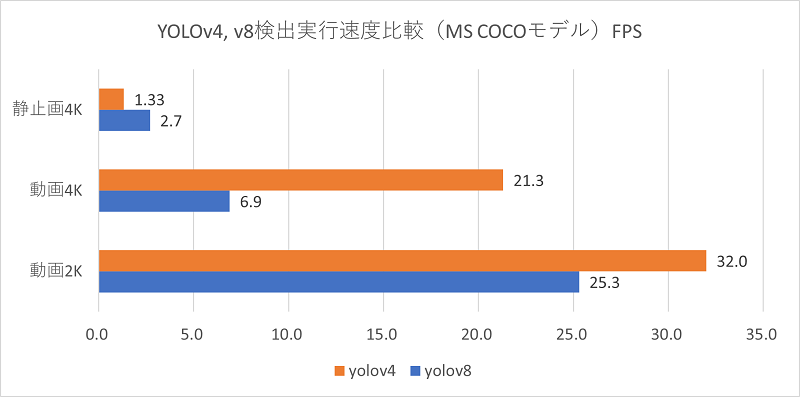
動画については2K、4KともYOLOv4の方が処理速度は速いことがわかります。特に4K動画はYOLOv8の3倍以上の速度という結果になりました。これに対し、静止画4KはYOLOv8の方が速く処理できます。
補足情報
YOLOv4では検出結果をJSON形式のテキストファイルで出力してくれましたが、YOLOv8では画像1枚につき1つのYOLO形式のテキストファイルで出力されます。
学習データとして再利用する場合は自分でアノテーションを作成しなくてよいため、効率的になりました。
ただし、テキストファイルでの出力はオプション"save_txt"、"save_conf"で設定する必要があります。
まとめ
結論:
・4K動画の検出はYOLOv4の方がYOLOv8よりも3倍以上高速
・静止画の検出はYOLOv8の方が約2倍速い
・YOLOv8では性能評価やチューニングの機能が充実している
・YOLOv4でカスタマイズしていた部分が影響を受ける(検出結果のアノテーションテキストの形式変更)
▼この記事を書いたひと
R&Dセンター 野原 佐知世
R&Dの「ちょっとしたものづくり」を主に担当。360°パノラマ、機械学習などシステム、画像処理を中心に活動しています。
おすすめの関連記事
機械学習・AIの最新記事
- 【エッジAI】Raspi5+SONY IMX500で30FPS枕木検出チャレンジ!~鉄道技術展2025デモ編 vol.25
- 【エッジAI】Raspi+SONY IMX500で30FPS物体検出チャレンジ!~オリジナルモデル、静止画・ログ保存編 vol.24
- 【エッジAI】Raspi5+SONY IMX500で30FPS物体検出チャレンジ!~環境整備編 vol.23
- 【エッジAI】Raspi5+SONY IMX500で30FPS物体検出チャレンジ!~検出実行編 vol.22
お問い合わせ
ご意見・ご質問などお気軽にお問い合わせ下さい。ナカシャクリエイテブ株式会社
●富士見事務所 TEL : 052-228-8744(交通部営業課) FAX : 052-323-3337(交通部共通)
〒460-0014 愛知県名古屋市中区富士見町13−22 ファミール富士見711 地図
PoCのお問い合わせ:交通部営業課
技術的なお問い合わせ:R&Dセンター






![]()

![]()