機械学習・AI【物体検出】vol.14 :YOLOv4 vs YOLOv3 ~ 同じデータセットを使った独自モデルの性能比較

これまでYOLOv3で作ってきた学習データを、無修正でYOLOv4でそのまま学習させると性能が上がるのかどうか?
また、検出速度の向上はあるのか?
今回はその辺りを検証し、報告します。
ただし、YOLOv4では新たな機能として、学習時に画像処理を行い、モザイクやブレなどを生じさせてデータを水増しする機能がありますが、今回は新しい機能を使わずに検証しています。この機能は、汎化性能を向上させる効果を期待できますので、後日改めて検証します。
結論:
・ YOLOv4では、v3と同じ学習データを無加工で使っても、モデルの正解率Precision、再現率Recall、F値が全体的に10%~向上する。
・ 学習に掛かる時間、検出速度はいずれも40%程度低下する。
※v4の新しい機能を使わない場合(v3と同等の機能だけを使った場合)であることに注意
学習データ
PCスペック
HP OMEN 880-000jp Desktop
i7 7700 3.6GHz*8、メモリ32GB
NVidia GeForce GTX1070 8GB
Windows10Professional 64bit
OpenCV 4.2.0
CUDA 10.1.105
cuDNN 7.6.0.64
学習時パラメータ
YOLOv3、YOLOv4の学習時パラメータは下記の通りです。
batch=64
subdivisions=32
width=416
height=416
学習時のグラフ
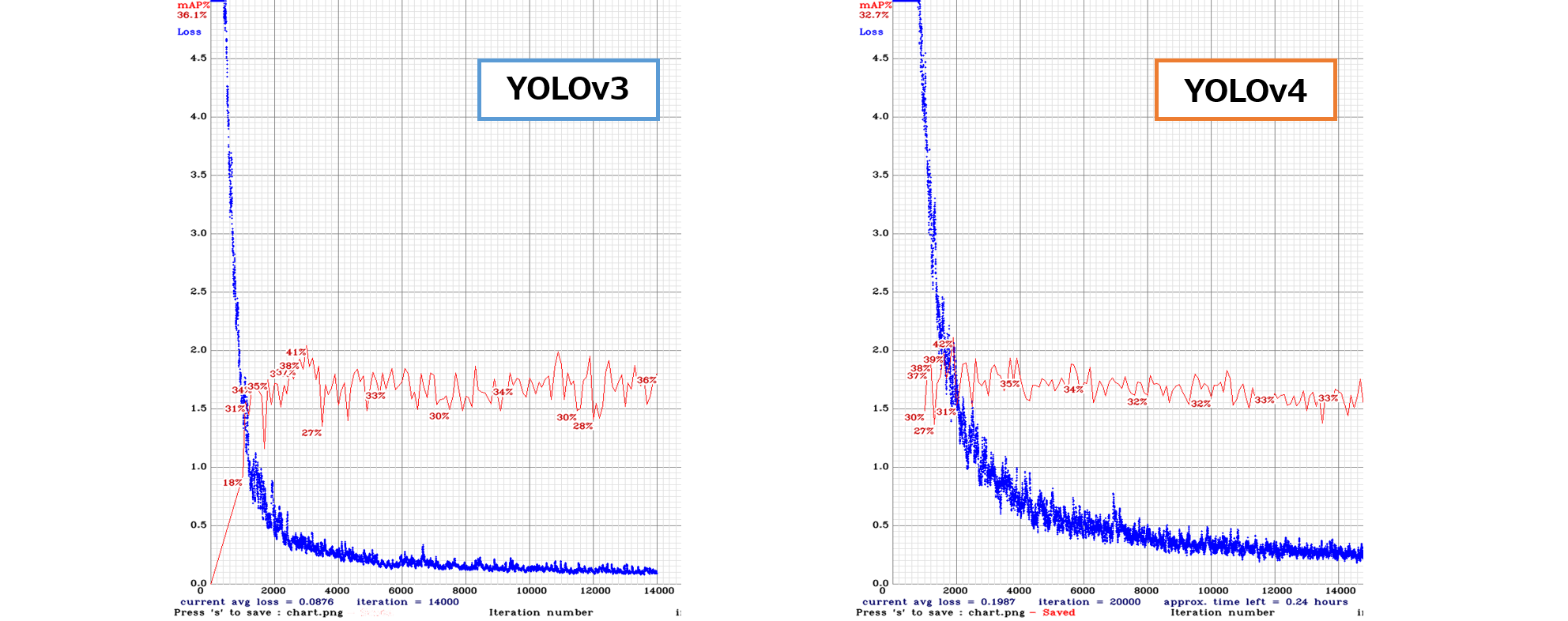
YOLOv4の方がlossが緩やかに減少していくのがわかります。
また、mAPはピークの位置と収束の仕方に違いがあります。
YOLOv3では、値の振れ幅が大きく、ピーク位置もイテレーションが3000のとき、11000のとき、と数回発生しており、なかなか収束の傾向が見られません。これに対し、YOLOv4の方ではピーク位置が2000イテレーションという早い段階で訪れており、その後はYOLOv3よりも緩やかに値が収束していきました。
YOLOv4ではmAPの立ち上がりが早く現れ、Lossの減少が遅い。
但し、モデルの構造がそもそも異なるため、最適な学習率がv3とv4で異なる可能性がある。
学習の処理時間
1000イテレーションに費やした時間
- YOLOv3:平均 100分
- YOLOv4:平均 136分
YOLOv4ではYOLOv3の場合より、おおよそ1.4倍の差があります。
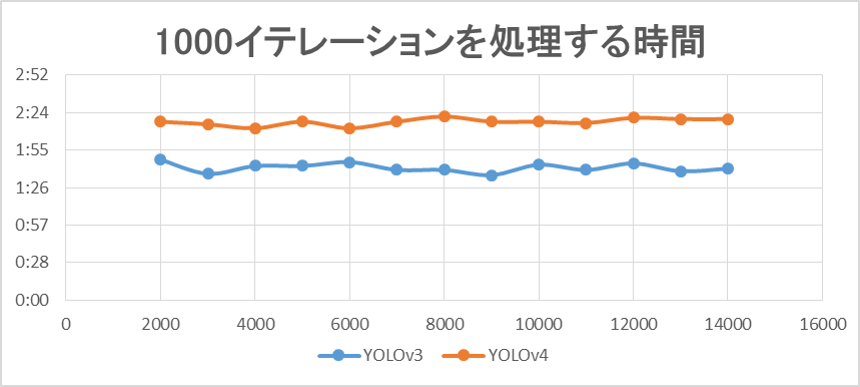
YOLOv4では時間が40%増しになる。
但し、学習時のメモリやCPUの機能に最適化した機能を用意しているので、改善の余地がある。
モデル性能
正解率:Precision
ここでは、1000イテレーションごとに作成されるweightsのうち、イテレーション回数5000以上のPrecisionの結果から中央値を算出して、比較しています。
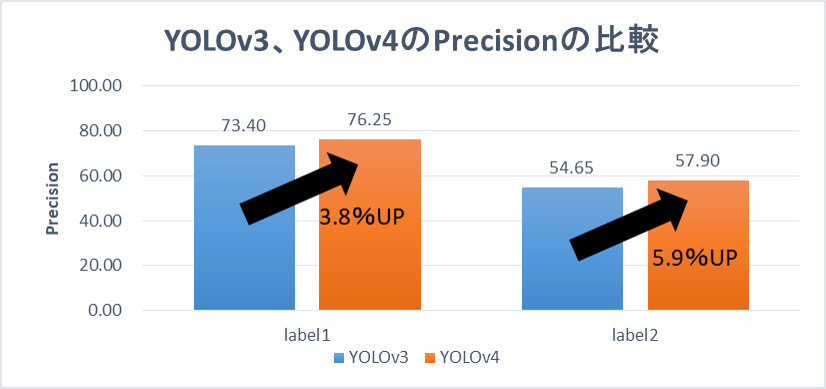
今回検証したモデルでは、Precisionが3~5%ほど向上しているのがわかります。
| label1 | label2 | |||
|---|---|---|---|---|
| YOLOv3 | YOLOv4 | YOLOv3 | YOLOv4 | |
| テスト用の画像数(枚) | 42 | 42 | 17 | 17 |
| 検出数(枚) | 28 | 31 | 11 | 15 |
| ->正解(枚) | 27 | 31 | 11 | 14 |
| ->不正解(枚) | 1 | 0 | 0 | 1 |
| 検出率(%) | 66.67 | 73.81 | 64.71 | 88.24 |
実際にYOLOv4のモデルで検出処理をしてみると、YOLOv3のときよりも検出数が上がっているのが確認できました。
上記とは別のモデルでも検証してみます。
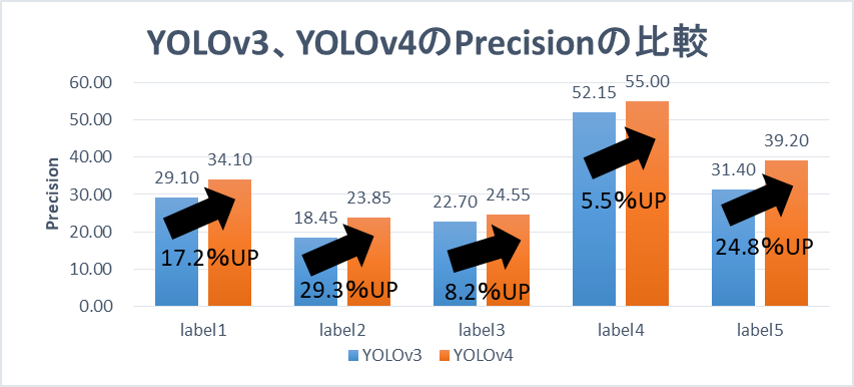
こちらのモデルでは、最大で約30%向上しています。
label3、label4のように数パーセントしか向上していないものもありますが、対象の特徴がわかりやすく検出しやすい場合や、YOLOv3におけるPrecisionの値が高いといった場合に、そのような傾向がみられました。
YOLOv4では、少なくとも数パーセント~30%程度のPrecisionの向上を期待できる。
再現率:RecallとF値
RecallとF値はbest.weightsの結果を比較しました。
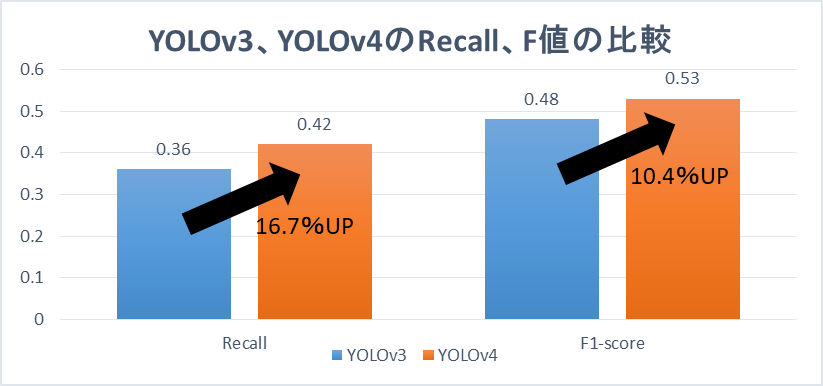
Precisionと同じく、RecallとF値についても、値が10%以上向上しているのが確認できました。
Recall、F値では10%の向上が見られる。
結論
YOLOv4では、YOLOv3と比較して学習の処理時間がかかるものの、その精度は以前よりも全体的に向上しているということがわかりました。
より精度を求めるのであれば、YOLOv4でモデルを再作成してみるのをお勧めします。
検出性能
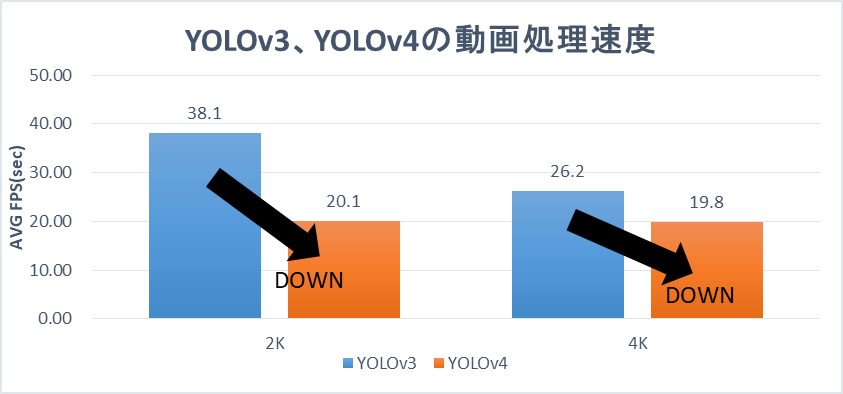
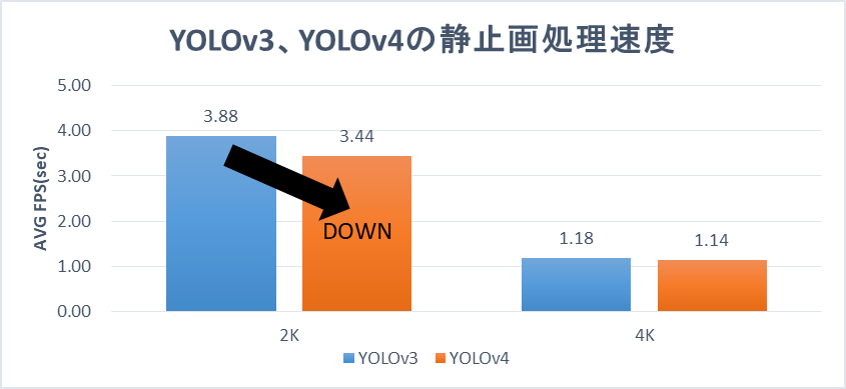
4K(3840x2160)と2K(1920x1080)の内容がまったく同じ動画、静止画に対して、YOLOv3とYOLOv4のモデルを使って検出を行い、その処理速度を比較しました。
動画
静止画
結論
動画の処理速度はYOLOv4の方が遅く、静止画の場合もYOLOv4の方が遅いかほぼ同等という結果が得られました。
モデルの性能は向上しますが、残念ながら検出の処理については、学習時と同様、YOLOv3よりも多くの時間が必要になります。
ちなみに、動画処理におけるベンチマークを確認してみると、
- YOLOv3:FPS=37.9
- YOLOv4:FPS=20.4
という値が得られました。
この結果から、YOLOv4では解像度に関わらずベンチマーク通りの能力が発揮されていることがわかります。一方で、YOLOv3の方では、解像度によって10fpsの差が生まれているので、その部分は改善されたと言えます。
動画を使った検出で30%の性能低下。静止画による検出ではほぼ同等。しかし4Kの処理が遅い。
但し、OpenCVやインテルCPUの機能への最適化によるチューニングが施されており、環境周りの見直しの後に再評価の必要がある。
ここではまだ検証出来ていないこと(TODO)
検出結果画像による比較
検出結果画像によるPrecison ,Recallなどの目視検証。
評価指標の妥当性判断
今回使用した学習時パラメータは、v3でベストと判断したものをそのまま使っていますが、モデル構造そのものが異なるので、本来であれば学習率やバッチサイズ、イテレーション回数などを広範囲に調査した上で、最適な条件で学習して比較するのがフェアです。
もしかするとスイートスポットがイテレーション2万回以上のところにあるかもしれませんし、Precision、Recall、F値の算出がv3とv4で異なっている可能性があります。
※特に正解のアノテーションが難しい不定形の対象の場合に、IoUがこれらの性能指標に大きな影響を持っていることが分かっています。
汎化性能の評価
YOLOv4では、データの水増しを内部で行うための機能が追加されており、汎化性能の向上に寄与すると推測されます。
今回、YOLOv3と全く同じ条件で、比較をしましたので、v4に最適な条件でチューニングした結果は、また変わって来ると思われます。
データ処理の効率化
mapコマンド周りが大きく改善されましたので、性能評価の後処理部分が大きく改善されている効果も期待できます。
総じて・・・
今回、v4で追加された機能をほとんど使わずに、ほぼv3同等の使い方をして、比較をしました。
まだまだv4の奥深い機能にはタッチ出来ていませんので、この辺りの探求をしていくことで、更に性能(特に速度面)の向上が見られると思います。
▼この記事を書いたひと
R&Dセンター 野原 佐知世
R&Dの「ちょっとしたものづくり」を主に担当。360°パノラマ、機械学習などシステム、画像処理を中心に活動しています。
おすすめの関連記事
- 【物体検出】vol.13 :Darknet YOLOv4をWindowsで動かす
- 【物体検出】vol.1 :Windowsでディープラーニング!Darknet YOLOv3(AlexeyAB Darknet)
- 【物体検出】vol.7 :YOLOv3をもっと便利に!魔改造のススメ
- 【物体検出】vol.3 :YOLOv3の独自モデル学習の勘所
機械学習・AIの最新記事
- 【エッジAI】Raspi5+SONY IMX500で30FPS枕木検出チャレンジ!~鉄道技術展2025デモ編 vol.25
- 【エッジAI】Raspi+SONY IMX500で30FPS物体検出チャレンジ!~オリジナルモデル、静止画・ログ保存編 vol.24
- 【エッジAI】Raspi5+SONY IMX500で30FPS物体検出チャレンジ!~環境整備編 vol.23
- 【エッジAI】Raspi5+SONY IMX500で30FPS物体検出チャレンジ!~検出実行編 vol.22
お問い合わせ
ご意見・ご質問などお気軽にお問い合わせ下さい。ナカシャクリエイテブ株式会社
●富士見事務所 TEL : 052-228-8733 FAX : 052-323-3337
〒460-0014 愛知県名古屋市中区富士見町13−22 ファミール富士見711 地図
交通部 R&Dセンター






![]()

![]()