機械学習・AI【物体検出】vol.17 :Darknet YOLOv4でRTX2080Superのベンチマーク(GTX1070の1.7倍!)

YOLOv3からYOLOv4への移行で、学習に係る時間が1.4倍になってしまったことを、【物体検出】vol.14 :YOLOv4 vs YOLOv3 ~ 同じデータセットを使った独自モデルの性能比較で書きました。
「このままではいけない!」
ということで、今回、処理PCのGPUをRTX2080 Superに換装し、YOLOv4を使ったベンチマークを実施しました。(ゲームなどのスコア比較はよく見かけますが、「YOLOで速くなるの?」という記事はなかなか見かけませんよね)
結論:
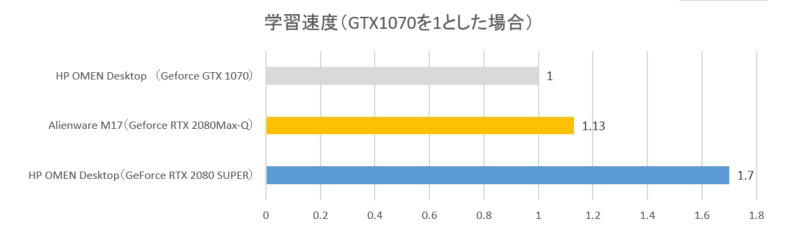
RTX2080Superは速い。対RTX2080(with Max-Q)比で150%、対GTX1070比で170%に高速化しました。
v3からv4で遅くなった分を、見事に取り返しました。
GPUの換装
GPUの取り付け
HP OMEN DesktopのGTX1070をRTX2080Superに換装します。
GPU二枚挿しにしたいところですが、電源容量が足りないので、泣く泣く換装(差し替え)です。

側面カバーを開け、GTX1070の電源コネクタを取り外します。
GTX1070を外します。
RTX2080Superを取り付けます。自重で垂れ下げるので、スペーサを下に置きます。
電源から余っている電源ケーブルを引き回します。
電源コネクタを2系統差し込みます。
側面カバーをもとに戻します。

最新ドライバーのインストール
GEFORCE EXPERIENCEから最新のディスプレイドライバをインストールします。
(ユーザ登録とサイトへのログインが必要です)
環境の再構築
darknetに必要な環境の確認(2020/05/13時点)
https://github.com/AlexeyAB/darknet
CMake >= 3.12
CUDA 10.0
OpenCV >= 2.4
cuDNN >= 7.0 for CUDA 10.0
GPU with CC >= 3.0
GPU:NVIDIA GeForce RTX 2080 SUPER
https://developer.nvidia.com/cuda-gpus#compute
GPU Compute Capability
Geforce RTX 2080 Ti 7.5
Geforce RTX 2080 7.5
インストール済みの環境を確認
■インストール済み各バージョン
cmake-3.14.4
cuda V10.2.89 windows10
cudnn v7.6.5 cuda10.2 windows10
OpenCV 4.3.0(バイナリ
VisualStudio2017
■各環境変数の設定確認
CUDA_PATH = C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2
CUDA_PATH_V10_1 = C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2
CUDNN_PATH = なし
OPENCV_DIR = C:\opencv4.3.0\opencv\build
PATH
→ C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\libnvvp
C:\opencv4.3.0\opencv\build\x64\vc15\bin
■python環境チェック
本体の場所
C:\ProgramData\Anaconda3\python.exe
ライブラリ等インストール先
(anaconda)C:\ProgramData\Anaconda3\Lib\site-packages
(pip)?
■各環境チェック
>> 実行ログ
C:\Users\rdcenter>nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2019 NVIDIA Corporation
Built on Wed_Oct_23_19:32:27_Pacific_Daylight_Time_2019
Cuda compilation tools, release 10.2, V10.2.89
C:\Users\rdcenter>where cudnn64_7.dll
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\bin\cudnn64_7.dll
C:\Users\rdcenter>python
Python 3.6.3 |Anaconda, Inc.| (default, Oct 15 2017, 03:27:45) [MSC v.1900 64 bit (AMD64)] on win32
C:\Users\rdcenter>where opencv_version
C:\opencv4.3.0\opencv\build\x64\vc15\bin\opencv_version.exe
darknetの再構築
■cmake
ENABLE_CUDA
ENABLE_CUDNN
ENABLE_OPENCV
ENABLE_CUDNN_HALF にチェックが入っていればOK
■configure
"configure"クリック後、特に問題がなければそのまま"generate"をクリック
■rebuild(VisualStudio)
構成でRelease、x64を選択
ソリューションエクスプローラー内にある'darknet'を右クリックして、プロパティを選択
C/C++ -> プリプロセッサ -> プリプロセッサの定義に「CUDNN_HALF」 があるか確認(なければ追記します)
ソリューションのビルドを実行
■ビルドしたdarknet.exeを実行する
・"pthereadVC2.dll"がないとエラーが出る場合
alexeyab_darknet_v4\3rdparty\pthreads\binからコピーしdarknet.exeと同じ場所に置く
・CUDA Errorが出る場合
再度、最新のディスプレイドライバをインストール。
darknet.exe detector test cfg/coco.data cfg/yolov4.cfg yolov4.weights -dont_show -ext_output < data/filelist.txt -out results/result.json >
results/result.txt
CUDA Error: CUDA driver version is insufficient for CUDA runtime version: No error
■正常に起動した例
cudnn_halfが有効になっている所がポイントです。
>> コマンド
darknet.exe detector demo cfg/coco.data cfg/yolov4.cfg yolov4.weights -dont_show -ext_output data/test.mp4 -prefix results/video/img -out_filename
results/video/result.mp4 > results/video/result.txt
>>実行ログ
darknet.exe detector demo cfg/coco.data cfg/yolov4.cfg yolov4.weights -dont_show -ext_output data/test.mp4 -prefix results/video/img -out_filename
results/video/result.mp4 > results/video/result.txt
CUDA-version: 10010 (11000), cuDNN: 7.6.0, CUDNN_HALF=1, GPU count: 1
OpenCV version: 4.3.0
0 : compute_capability = 750, cudnn_half = 1, GPU: GeForce RTX 2080 SUPER
layer filters size/strd(dil) input output
(省略
ベンチマーク
今回使用したPC
RTX2080 Super(HP OMEN Desktop )
GPU : NVIDIA GeForce GTX2080 SUPER 8GBRAM
CPU : Intel Core i7-7700 3.6GHz(4コア、論理8)
RAM:32GB
cuda V10.1.105 windows10
cudnn v7.6.0 cuda10.1 windows10
OpenCV 4.3.0
RTX2080 MAX-Q(Alienware M17)
GPU : NVIDIA GeForce GTX2080 with Max-Q Design 8GBRAM
CPU : Intel Core i7-9750 2.6GHz(6コア、論理12)
RAM:16GB
cuda V10.1.243 windows10
cudnn v7.6.4 cuda10.1 windows10
OpenCV 4.3.0
GTX1070(HP OMEN Desktop) GPU : NVIDIA GeForce GTX1070 8GBRAM
CPU : Intel Core i7-7700 3.6GHz(4コア、論理8)
RAM:32GB
cuda 10.1.105 windows10
cudnn v7.6.0 cuda10.1 windows10
OpenCV 4.2.0
ベンチマークの方法
YOLOv4を同じcfg、同じデータセット、同じモデル(weight)を用いて、同条件で学習させ、1000イテレーション毎の時間を計測する。
結果(学習)
| PC | 学習時間 |
|---|---|
| HP OMEN Desktop(GeForce RTX 2080 SUPER) | 80分 |
| Alienware M17(Geforce RTX 2080Max-Q) | 120分 |
| HP OMEN Desktop(Geforce GTX 1070) | 136分 |
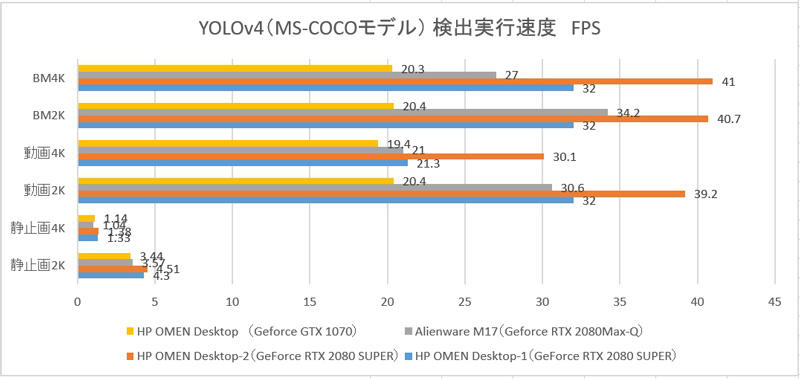
結果(検出)
静止画:1801枚
動画:1796フレーム
darknet.exe detector demo cfg/coco.data cfg/yolov4.cfg yolov4.weights -dont_show -ext_output data/test_2K.mp4 > results/result_test_2K_v4.txt
ベンチマーク:1796フレーム
darknet.exe detector demo cfg/coco.data cfg/yolov4.cfg yolov4.weights -benchmark data/test_2K.mp4 > results/test_2K.txt
| PC | 静止画2K | 静止画4K | 動画2K | 動画4K | BM2K | BM4K |
|---|---|---|---|---|---|---|
| HP OMEN Desktop-1(GeForce RTX 2080 SUPER) | 4.30 | 1.33 | 32.0 | 21.3 | 32.0 | 32.0 |
| HP OMEN Desktop-2(GeForce RTX 2080 SUPER) | 4.51 | 1.38 | 39.2 | 30.1 | 40.7 | 41.0 |
| Alienware M17(Geforce RTX 2080Max-Q) | 3.57 | 1.04 | 30.6 | 21.0 | 34.2 | 27.0 |
| HP OMEN Desktop (Geforce GTX 1070) | 3.44 | 1.14 | 20.4 | 19.4 | 20.4 | 20.3 |
▼この記事を書いたひと
R&Dセンター 野原 佐知世
R&Dの「ちょっとしたものづくり」を主に担当。360°パノラマ、機械学習などシステム、画像処理を中心に活動しています。
機械学習・AIの最新記事
- 【エッジAI】Raspi5+SONY IMX500で30FPS枕木検出チャレンジ!~鉄道技術展2025デモ編 vol.25
- 【エッジAI】Raspi+SONY IMX500で30FPS物体検出チャレンジ!~オリジナルモデル、静止画・ログ保存編 vol.24
- 【エッジAI】Raspi5+SONY IMX500で30FPS物体検出チャレンジ!~環境整備編 vol.23
- 【エッジAI】Raspi5+SONY IMX500で30FPS物体検出チャレンジ!~検出実行編 vol.22
お問い合わせ
ご意見・ご質問などお気軽にお問い合わせ下さい。ナカシャクリエイテブ株式会社
●富士見事務所 TEL : 052-228-8733 FAX : 052-323-3337
〒460-0014 愛知県名古屋市中区富士見町13−22 ファミール富士見711 地図
交通部 R&Dセンター






![]()

![]()