機械学習・AI【物体検出】vol.6 :YOLOv3で様々な学習済モデルを検証する

YOLOv3では、精度と実行速度の異なるいくつかのPre-Trained Model(学習済モデル)が用意されています。
公開されているモデルの学習データは、すべてCOCO。
特に、デフォルトで提供されているYOLOv3モデルの他にも、実はより精度の高い(その代わり速度が若干遅い)SPP(Spatial Pyramid Pooling Based YOLO)というモデルもあります。
正確さよりもリアルタイム性や軽量さを要求される用途では、Tiny-YOLOという小さいモデルも選択できます。
今回は、v3と名の付くこの3つのモデルを、様々なパラメータで実行し、速度と精度を検証します。
参考:YOLOv3 論文
公開されている学習済モデルとmAP、FPS一覧
参考サイト:
https://github.com/AlexeyAB/darknet
https://pjreddie.com/darknet/yolo/
Pre-trained models
| yolov3-openimages.cfg (247 MB COCO Yolo v3) |
requires 4 GB GPU-RAM | - | - | https://pjreddie.com/media/files/yolov3-openimages.weights |
| yolov3-spp.cfg (240 MB COCO Yolo v3) |
requires 4 GB GPU-RAM | mAP=60.6 | 20FPS | https://pjreddie.com/media/files/yolov3-spp.weights |
| yolov3.cfg (236 MB COCO Yolo v3) |
requires 4 GB GPU-RAM | mAP=55.3 | 35FPS | https://pjreddie.com/media/files/yolov3.weights |
| yolov3-tiny.cfg (34 MB COCO Yolo v3 tiny) |
requires 1 GB GPU-RAM | mAP=33.1 | 220FPS | https://pjreddie.com/media/files/yolov3-tiny.weights |
| yolov2.cfg (194 MB COCO Yolo v2) |
requires 4 GB GPU-RAM | mAP=48.1 | 40FPS | https://pjreddie.com/media/files/yolov2.weights |
| yolo-voc.cfg (194 MB VOC Yolo v2) |
requires 4 GB GPU-RAM | - | - | http://pjreddie.com/media/files/yolo-voc.weights |
| yolov2-tiny.cfg (43 MB COCO Yolo v2) - |
requires 1 GB GPU-RAM | mAP=23.7 | 244FPS | https://pjreddie.com/media/files/yolov2-tiny.weights |
| yolov2-tiny-voc.cfg (60 MB VOC Yolo v2) |
requires 1 GB GPU-RAM | - | - | http://pjreddie.com/media/files/yolov2-tiny-voc.weights |
| yolo9000.cfg (186 MB Yolo9000-model) - |
requires 4 GB GPU-RAM | - | - | http://pjreddie.com/media/files/yolo9000.weights |
検証方法
動画
元々4Kで撮影した動画を、FHD(2K:1920x1080)、HD(1440×1080)、VGA(640x480)にダウンコンバートし、この4種類の動画(mp4)を下記のコマンドでリアルタイムに物体検出する。
コマンド
darknet detector demo cfg/coco.data cfg/yolov3-spp.cfg yolov3-spp.weights -thresh 0.5 data/road/01.mp4 -dont_show 1 -out_filename results/road/01_out.mp4
処理環境
HP OMEN 880-000jp Desktop
i7 8700 3.2GHz*8、メモリ32GB
NVidia GeForce GTX1070 8GB
Windows10Professional 64bit
CUDA:10.1
cuDNN:7.5.1
書き出し先:内蔵HDD(7200rpm)
精度の違い
精度は、静止画に書き出した状態で、同じフレームをどのように認識したか、検出すべきものを検出できているかどうか?を実際の検出画像を元に評価します。
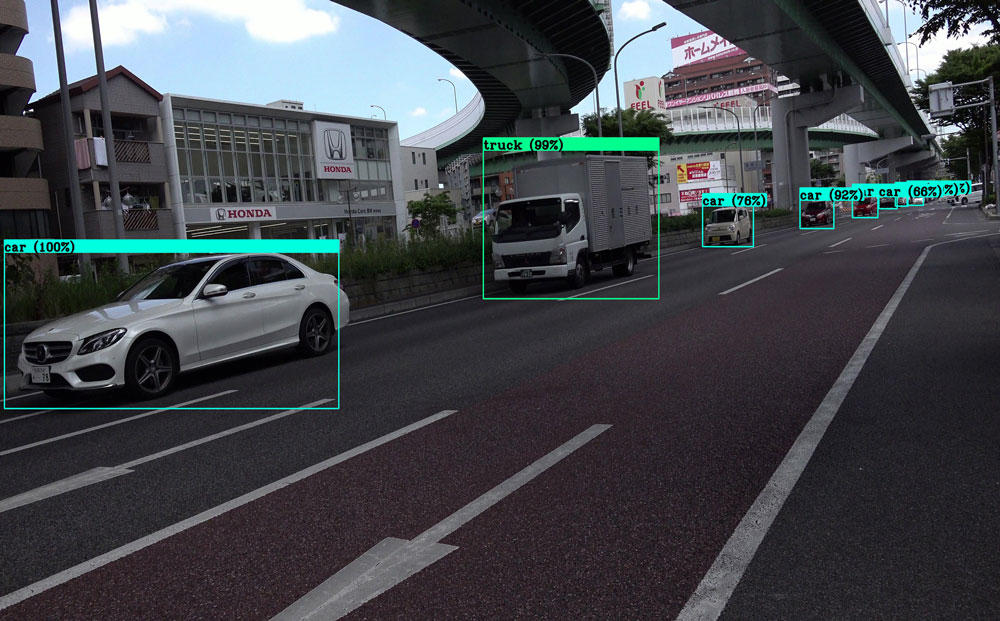
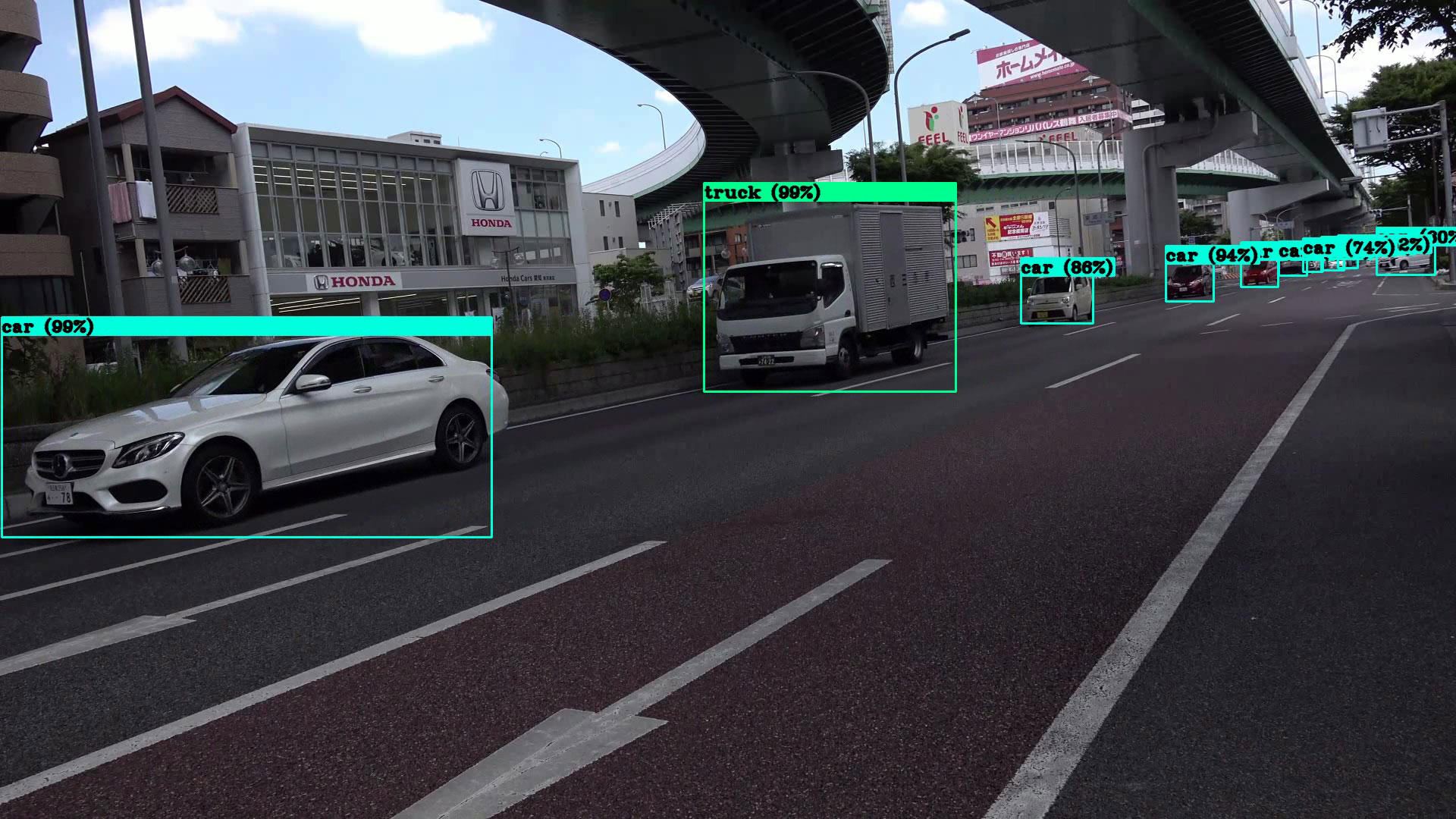
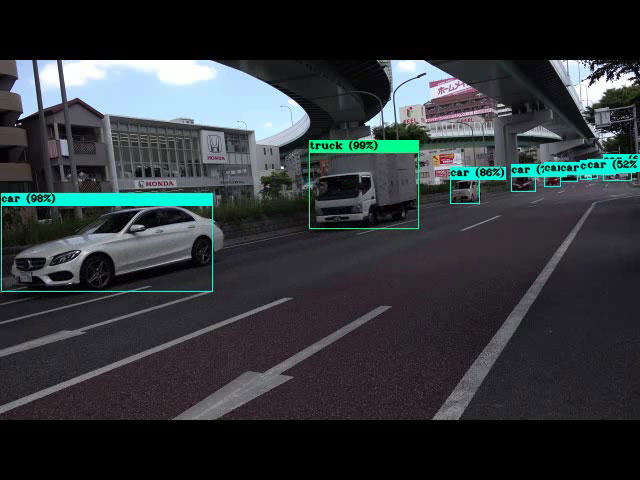
| v3-tiny | v3 | v3-spp |
|---|---|---|
 |
 |
 |
tinyでは大きなものしか認識されていません。検出数:2と検出漏れが多く、枠が二重で検出されているなど、結果がかなり怪しいです。
v3では、遠くのトラック(普通車の陰になっている)や遠方の車両を漏らしていますが、tinyよりも精度は高いです。検出数:6
v3-sppは、大きなものも小さなものも検出できています。ワンボックス車両をトラックと誤認識しています。検出数:8で最も検出漏れが少なく、精度も高い結果となっています。
モデル毎の比較では、v3-sppの検出精度が最も良い結果となりました。マルチスケール検出の手法によって、小さなものまで良く拾えていると推測できます。
速度の違い
処理速度に影響を与えると思われる条件として、下記があります:
- 動画の画素数
- 検出時の表示有り無し
- ログ保存有無
- 静止画保存有無
モデル種類&動画画素数
| 4K | 2K | HD | VGA | |
|---|---|---|---|---|
| tiny-yolo | FPS 18-20 | FPS 70-80 | FPS 100-110 | FPS 100-110 |
| v3 | FPS 18-20 | FPS 20-21 | FPS 20-21 | FPS 20-21 |
| v3-spp | FPS 18-20 | FPS 20-21 | FPS 20-21 | FPS 20-21 |
 |
 |
 |
 |
tinyでは、動画画素数の影響が如実に出ます。VGAサイズでは、なんと100-110fpsというスピードになりました。(検出の精度が良くないですが)
v3とv3-sppの場合、4Kの場合を除いて、それ以下の解像度の場合に20-21fpsが性能の上限のようです。tinyのようには解像度の影響が出ません。
4Kの場合は、tinyでもv3でもv3-sppでも18-20fpsと違いがありませんでした。
動画表示有無(4K映像の場合)
動画非表示/表示の際"-dont_show 1"を付ける/付けない
| 動画表示有 | 動画表示無 |
|---|---|
| FPS 13-15 | FPS 18-20 |
モデルがv3で4K動画を処理する場合、表示なし:18-20fps→表示あり:13-15fpsと動画表示有無で5fps(25%)程度の速度低下がありました。VGAの場合は、表示なし:36fps→表示あり:34fpsと影響は小さいです。
静止画書き出し有無(4K映像の場合)
動画から静止画に書き出す際"-prefix results/road/01/frame_"を付ける/付けない
| 静止画書き出し有 | 静止画書き出し無 |
|---|---|
| FPS 3 | FPS 18-20 |
静止画の書き出しを行う/行わないは、とても大きな影響があります。GPU処理に比べ、HDDへのファイル書き込みが遅いことが主な原因と推測できます。4Kの場合、静止画での書き出しを行うと処理に6倍の時間が掛かります。
ログ書き出し有無(4K映像の場合)
"-out results/C0010_out.json > results/C0010.txt"を付ける/付けない
| ログ書き出し有 | ログ書き出し無 |
|---|---|
| FPS 18-20 | FPS 18-20 |
ログの書き出しは、(意外にも)処理速度そのものに大した影響はなさそうです。4Kの18-20fpsに対してなので、差が大きく出なかったのかもしれません。
まとめ
今回のテスト環境では、VGAサイズの動画を使った場合に、 公式サイトに記載されているような結果(v3:35fps、v3-spp:20fps、tiny:220fps)に近い結果(v3:36fps、v3-spp:20-21fps、tiny:180-200fps)が得られました。
今回は試していませんが、mAP=48.1、40FPSというスペックを見る限り、v3-tinyの代わりにv2を採用しても良いかもしれません。
GPUリソースをふんだんに使えるPCで実行するなら断然v3-sppが良い。
処理速度が必要な場合でも、tinyの採用は怪しい。
(検出精度を犠牲にしても、"必要のないくらい高速"に意味がある用途ならOK)
せめてv3程度の認識は欲しい。
▼この記事を書いたひと

R&Dセンター 陸 依柳
撮影、お城、戦国、ICT、サブカルチャー...常に面白く、新しいものに惹かれるタイプです。地方の戦国イベントによく参加しています☆
おすすめの関連記事
- 【物体検出】vol.5 :YOLOv3のファンクションと引数のまとめ(私家版)
- 【物体検出】vol.4 :YOLOv3をWindows⇔Linuxで相互運用する
- 【物体検出】vol.3 :YOLOv3の独自モデル学習の勘所
- 【物体検出】vol.2 :YOLOv3をNVIDIA Jetson Nanoで動かす
機械学習・AIの最新記事
- 【エッジAI】Raspi5+SONY IMX500で30FPS枕木検出チャレンジ!~鉄道技術展2025デモ編 vol.25
- 【エッジAI】Raspi+SONY IMX500で30FPS物体検出チャレンジ!~オリジナルモデル、静止画・ログ保存編 vol.24
- 【エッジAI】Raspi5+SONY IMX500で30FPS物体検出チャレンジ!~環境整備編 vol.23
- 【エッジAI】Raspi5+SONY IMX500で30FPS物体検出チャレンジ!~検出実行編 vol.22
お問い合わせ
ご意見・ご質問などお気軽にお問い合わせ下さい。ナカシャクリエイテブ株式会社
●富士見事務所 TEL : 052-228-8733 FAX : 052-323-3337
〒460-0014 愛知県名古屋市中区富士見町13−22 ファミール富士見711 地図
交通部 R&Dセンター






![]()

![]()