AR/VR/画像処理【機械の目 Vol.4】4K動画から生成した静止画をディープラーニングに利用する

ディープラーニングによる画像認識技術には、画像に何が写っているのかを分類する"分類(Classification)"や全体として何を表しているのかを認識する"認識(Recognition)"とどこに何が写っているのかを抽出する"物体検出(Detection)"があります。
弊社では、「何が写っているのかを分類した上で、それがどこに写っているのかを提示する」仕組みとして、Tensorflow+KerasのSSD(SingleshotMultiDetector※)を検証しています。
※SSD:1枚の画像から複数の物体を検出する。
技術開発の目的(ゴール)
- 人が巡視しなければいけない場面を映像撮影で代用したい
- 映像の中身を人が実時間で確認する行為を減らしたい
- 映像に何が写っているのかを自動的に抽出、判定したい
- 撮影日の異なる同一地点の変化を知りたい
ディープラーニングモデルの作成
画像、映像に何が写っているのかの定義を、人間がコンピュータ(ディープラーニングモデル)に教えることを、 "学習させる"と言います。学習に使うデータを、教師データと言い、これらをどれだけ用意して、何回学習させるか?によってモデルの抽出率※、認識精度※や、汎化性能※が高まります。
- 0:画像、映像データの準備
- 1:区分の決定
- 2:アノテーションデータの作成
- 3:モデルの学習
- 4:モデルの評価
※抽出率:対象をどれだけ漏れなく抽出できるか
※認識精度:認識した結果がどれくらい合っているか(どれくらい間違いなく認識したか)
※汎化性能:学習させた画像、映像以外の同対象を認識できるかどうか?(自分が見たもの以外の特徴をどれだけ認識できるか)
当社のルール
1区分最低100枚。学習回数は50回実行する。Accuracyが0.7以上得られれば成功。それ以下は失敗。
SSD300(VGG16派生モデル)のモデルを転移学習。
教師データに4K動画からの静止画を活用する
SSDによる高速道路設備の一般物体認識モデル
高速道路上を走行する車両から撮影した前方映像を使って、案内標識、キロポスト、クッションポール、跨道橋、
クッションドラム等の高速道路設備の物体認識をします。
GPSによる位置情報と、画像/映像に何が写っているのかの情報を合わせて、データベースの検索情報として活用できます。
- 跨道橋
- 案内標識
- ジョイント
- クッションポール
- クッションドラム
- 非常電話
- キロポスト







SSDによる土木設備の変状モデル
高速道路設備・施設コンクリート部の剥落、ガードレール等金属部分の錆、付近植生の変化を認識します。
異常個所の特徴をうまくモデル化できれば、変状箇所と位置情報を紐づけたデータベースを自動的に作成できます。
- 剥落
- 植生
物体認識の結果をデータベースの検索キーワードとして活用する例
- μファイルジオでキーワード指定した検索結果(地図表示)
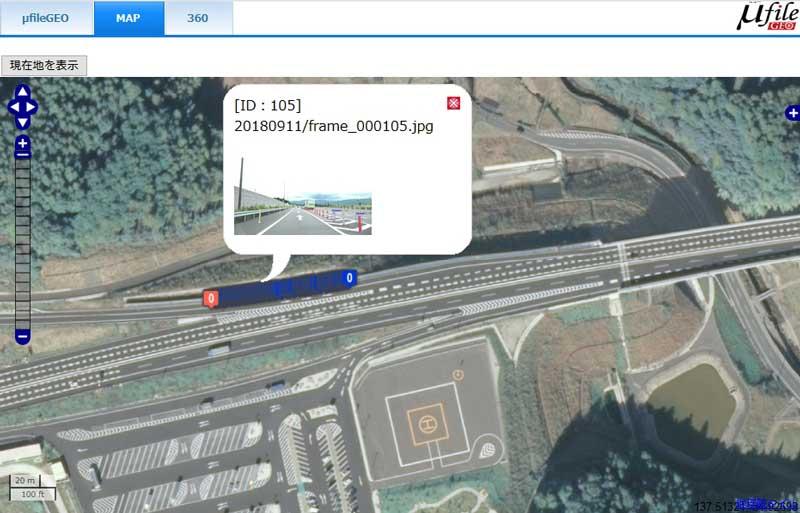
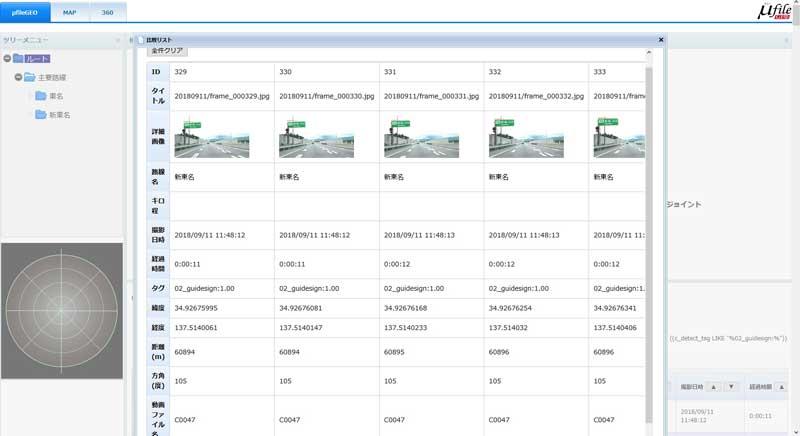
物体認識の結果と位置情報から、同一地点の映像を特定する例
- μファイルジオで位置情報、フレーム位置、物体認識タグを指定して、類似画像を検索した結果(比較表示)
▼この記事を書いたひと

R&Dセンター 松井 良行
R&Dセンター 室長。コンピュータと共に35年。そしてこれからも!
おすすめの関連記事
機械学習・AIの最新記事
- 【オープンイノベーション】vol.42:YOLOv11, YOLOv12をGeForce RTX 4090で動かす
- 【オープンイノベーション】vol.28:鉄道保線用物体検出AI「遊間」モデル作成
- 【オープンイノベーション】vol.26:何がどう変わった?Ultralytics YOLOv8のレビュー
- 特許を取得しました "分布図作成装置、分布図作成方法、及び、プログラム"(特許6970946)"
AR/VR/画像処理の最新記事
- 特許を取得しました "情報処理装置及び方法(特許第6704134号)"
- 【360°映像技術の活かし方・ノウハウ vol.9】プロ用360カメラInsta360 TITANを試す!
- 【物体検出】vol.8 :YOLOv3で360パノラマの"全方位物体検出"を実現!(特許第6704134号)
- 【360°映像技術の活かし方・ノウハウ vol.8】膨大な360°パノラマをキーワード検索するμファイル
お問い合わせ
ご意見・ご質問などお気軽にお問い合わせ下さい。ナカシャクリエイテブ株式会社
●富士見事務所 TEL : 052-228-8733 FAX : 052-323-3337
〒460-0014 愛知県名古屋市中区富士見町13−22 ファミール富士見711 地図
交通部 R&Dセンター






![]()

![]()